# Run Gemma 2 Powered Chatbot on GKE Autopilot
## 目的
任務 1. 準備 GKE Autopilot 叢集
任務 2. 部署 Ollama
任務 3. 使用 Ollama CLI 與 Gemma 2 互動
任務 4. 部署 Open WebUI,打造更友善的 Chatbot 互動介面
# Run Gemma 2 Powered Chatbot on GKE Autopilot
生成式 AI 正以驚人的速度發展,大型語言模型 (LLM) 更是其中的佼佼者。這些模型展現了前所未有的語言理解和生成能力,為各個領域帶來革命性的應用。
然而,使用專有 LLM 模型也存在一些風險: * 成本考量: 使用專有模型 API 通常需要支付高昂的費用,尤其是在需要處理大量數據或高併發請求的情況下。 * 資料隱私: 將敏感資料傳輸到第三方 API 可能存在資料洩露的風險。 * 功能限制: 專有模型的功能和客製化程度受限於 API 提供者。
開源 LLM 模型,如 Gemma 2,為我們提供了另一種選擇。 它們允許使用者自由地使用、修改和部署模型,無需擔心成本和資料隱私問題,並能根據自身需求進行客製化。
請依照以下步驟建立 GKE Autopilot 叢集:
設定環境變數:為了方便後續操作,我們先設定叢集名稱和區域的環境變數。請將以下指令複製貼上至 Cloud Shell 中執行:
CLUSTER_NAME=my-cluster CLUSTER_LOCATION=us-central1
建立叢集: 執行以下指令建立 GKE Autopilot 叢集:
gcloud container clusters create-auto ${CLUSTER_NAME} \
--location=${CLUSTER_LOCATION}
此指令會在 us-central1 區域建立一個名為 my-cluster 的 GKE Autopilot 叢集。您可以根據需求修改叢集名稱和區域。
驗證叢集狀態:建立叢集需要一些時間,數分鐘後您可以使用以下指令驗證叢集狀態:
kubectl cluster-info
如果叢集運作正常,您會看到類似以下的輸出訊息,顯示 Kubernetes 控制平面、服務等資訊:
<aside> 💡 Kubernetes control plane is running at https://34.55.86.35 GLBCDefaultBackend is running at https://34.55.86.35/api/v1/namespaces/kube-system/services/default-http-backend:http/proxy KubeDNS is running at https://34.55.86.35/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy Metrics-server is running at https://34.55.86.35/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'. </aside>
## 任務 2. 部署 Ollama
GKE Autopilot 簡化了 Kubernetes 的操作,讓您擺脫基礎架構管理的負擔,專注於應用程式開發。您只需在 PodSpec 中定義所需的硬體資源,GKE Autopilot 便會自動挑選最合適的節點來運行您的 Ollama 模型。在本例中,由於我們指定了需要 NVIDIA L4 GPU,GKE Autopilot 會將 Ollama 部署到配備 GPU 的節點上。
Ollama 需要穩定的儲存空間來存放模型檔案,因此我們使用 StatefulSet 來部署。StatefulSet 能夠確保每個 Pod 擁有獨一無二的網路識別,並且在重新啟動或遷移後仍能保留其儲存空間。StatefulSet 中的 Persistent Volume 能夠將模型檔案持久化儲存,避免每次啟動 Pod 都需要重新下載模型,節省時間並提升效率。
請依照以下步驟部署 Ollama:
建立 YAML 檔案: 使用 Cloud Shell Editor 建立一個名為 ollama.yaml 的檔案,並將以下內容複製貼上:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: ollama
spec:
selector:
matchLabels:
app: ollama
serviceName: ollama
template:
metadata:
labels:
app: ollama
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
cloud.google.com/gke-accelerator-count: "1"
containers:
- name: ollama
image: ollama/ollama
ports:
- containerPort: 11434
resources:
limits:
nvidia.com/gpu: "1"
volumeMounts:
- name: ollama
mountPath: /root/.ollama
volumeClaimTemplates:
- metadata:
name: ollama
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard-rwo
resources:
requests:
storage: 30Gi
---
apiVersion: v1
kind: Service
metadata:
name: ollama
spec:
selector:
app: ollama
clusterIP: None
ports:
- port: 11434
部署 Ollama: 儲存 ollama.yaml 檔案後,在 Cloud Shell 中執行以下指令:
kubectl apply -f ollama.yaml
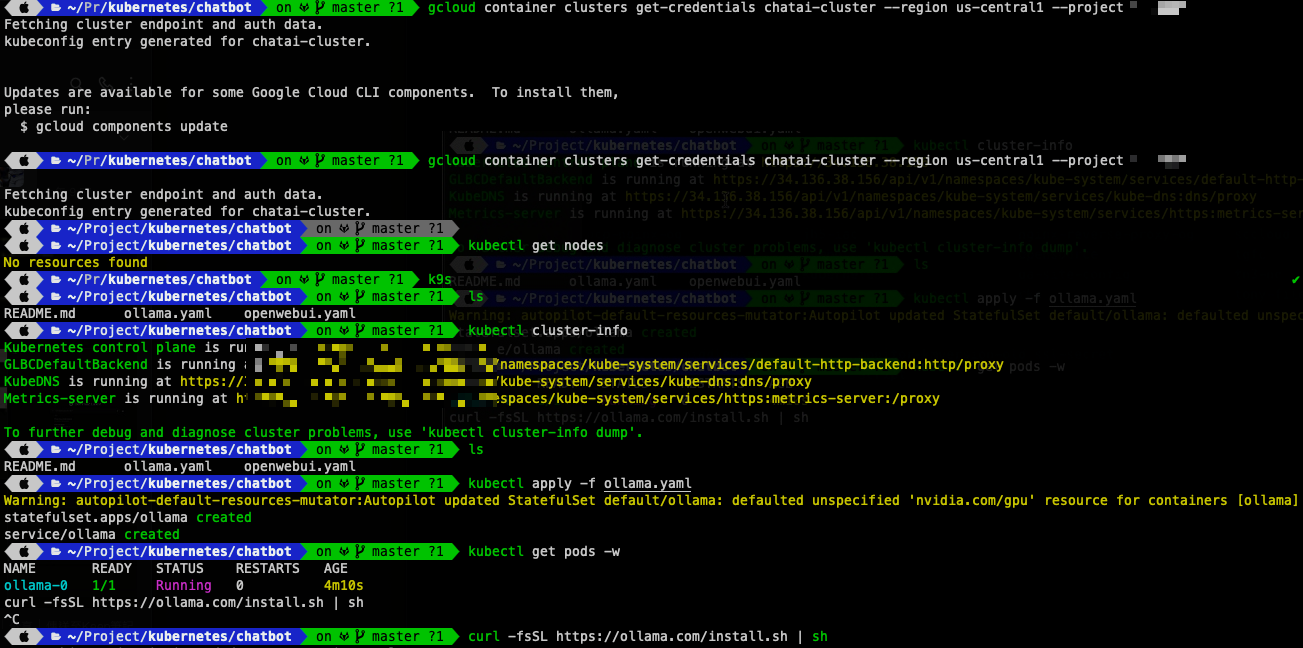
確認部署狀態: 執行以下指令觀察 Pod 的狀態:
kubectl get pods -w
等待 ollama-0 Pod 變成 Running 狀態,表示 Ollama 已成功部署。
透過以上步驟,您已將 Ollama 模型部署至 GKE Autopilot。StatefulSet 確保了 Ollama 模型的穩定運行和資料持久化,讓您的 LLM 應用程式更加可靠。接下來,我們將使用 Ollama CLI 來取得 Gemma 2 模型並且與其進行互動。
## 任務 3. 使用 Ollama CLI 與 Gemma 2 互動
在這個任務中,我們將使用 Ollama CLI 與部署在 GKE Autopilot 上的 Ollama server 互動。Ollama CLI 是一個命令列工具,讓您可以輕鬆地管理和使用 Ollama 模型。
請依照以下步驟操作:
安裝 Ollama CLI:在 Cloud Shell 中執行以下指令安裝 Ollama CLI:
curl -fsSL https://ollama.com/install.sh | sh
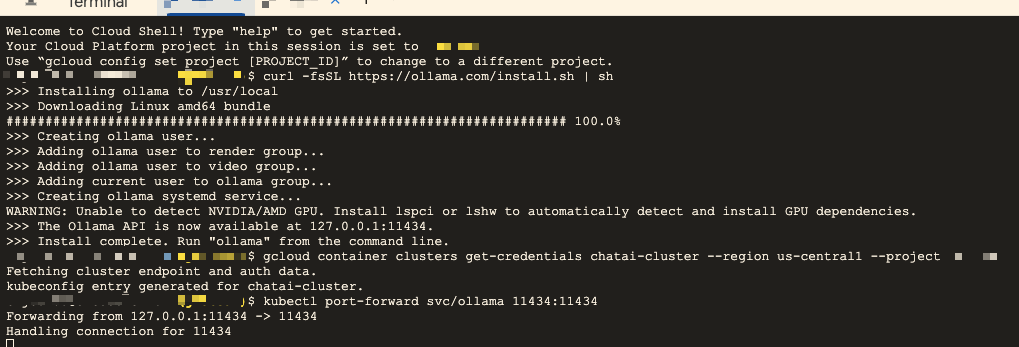
安裝過程中會出現一些訊息,如下所示:
<aside> 💡 >>> Installing ollama to /usr/local >>> Downloading Linux amd64 bundle ############################################# 100.0%#=#=# >>> Creating ollama user... >>> Adding ollama user to render group... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... WARNING: Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to automatically detect and install GPU dependencies. >>> The Ollama API is now available at 127.0.0.1:11434. >>> Install complete. Run "ollama" from the command line. </aside>
將 Ollama 服務端口轉發到本地: 執行以下指令,將 Ollama 服務的 11434 端口轉發到本地的 11434 端口:
kubectl port-forward svc/ollama 11434:11434
這個指令會建立一個連線,讓您可以透過本機的 11434 端口訪問叢集中的 Ollama 服務。請保持這個終端視窗開啟,不要關閉。
分割終端視窗: 點擊 Cloud Shell 視窗上方的「垂直分割」按鈕,將終端視窗分割成兩個分頁。
在新分頁中執行 Gemma 2 模型: 在新的終端分頁中,設定 OLLAMA_HOST 環境變數,指定 Ollama API 的地址,然後使用 ollama run 指令執行 Gemma 2 模型:
OLLAMA_HOST=http://localhost:11434 ollama run gemma2
執行成功後,您會看到類似以下的輸出,表示 Gemma 2 模型已啟動,並準備好接收您的輸入:
<aside> 💡 >>> 現在您可以輸入文字與 Gemma 2 模型互動,例如: >>> 你好! </aside>
Gemma 2 模型會根據您的輸入產生回應。
透過以上步驟,您已成功使用 Ollama CLI 與部署在 GKE Autopilot 上的 Gemma 2 模型互動。您可以嘗試不同的輸入,體驗 Gemma 2 模型的強大功能。
## 任務 4. 部署 Open WebUI,打造更友善的 Chatbot 互動介面
Ollama CLI 提供了基本的命令列互動功能,但若要使用更完整的 Chatbot 介面,我們可以部署 Open WebUI。Open WebUI 是一個開源的網頁介面,讓您可以透過圖形化介面與 Ollama 模型互動,體驗更便捷、更友善的 LLM 使用體驗。
請依照以下步驟部署 Open WebUI:
建立 YAML 檔案: 使用 Cloud Shell Editor 建立一個名為 openwebui.yaml 的檔案,並將以下內容複製貼上:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: openwebui
spec:
selector:
matchLabels:
app: openwebui
serviceName: openwebui
template:
metadata:
labels:
app: openwebui
spec:
containers:
- name: openwebui
image: ghcr.io/open-webui/open-webui:main
ports:
- containerPort: 8080
env:
- name: OLLAMA_BASE_URL
value: http://ollama:11434
- name: WEBUI_AUTH
value: "False"
resources:
requests:
cpu: "1"
memory: 1Gi
limits:
cpu: "1"
memory: 1Gi
volumeMounts:
- name: openwebui
mountPath: /app/backend/data
volumeClaimTemplates:
- metadata:
name: openwebui
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard-rwo
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: Service
metadata:
name: openwebui
spec:
type: LoadBalancer
selector:
app: openwebui
ports:
- port: 80
targetPort: 8080
部署 Open WebUI: 儲存 openwebui.yaml 檔案後,在 Cloud Shell 中執行以下指令部署 Open WebUI:
kubectl apply -f openwebui.yaml
取得 Load Balancer IP 地址: 執行以下指令取得 Load Balancer 的外部 IP 地址:
kubectl get service openwebui
在輸出結果中,找到 EXTERNAL-IP 欄位,即可看到 Load Balancer 的 IP 地址。
稍等片刻,Open WebUI 介面就會載入完成。您可以在介面中選擇 Gemma 2 模型,並開始進行互動。
透過瀏覽器訪問 Open WebUI: 開啟瀏覽器,並在網址列輸入 http:// (將 替換成您取得的 Load Balancer IP 地址)。
可以自行下載其它model
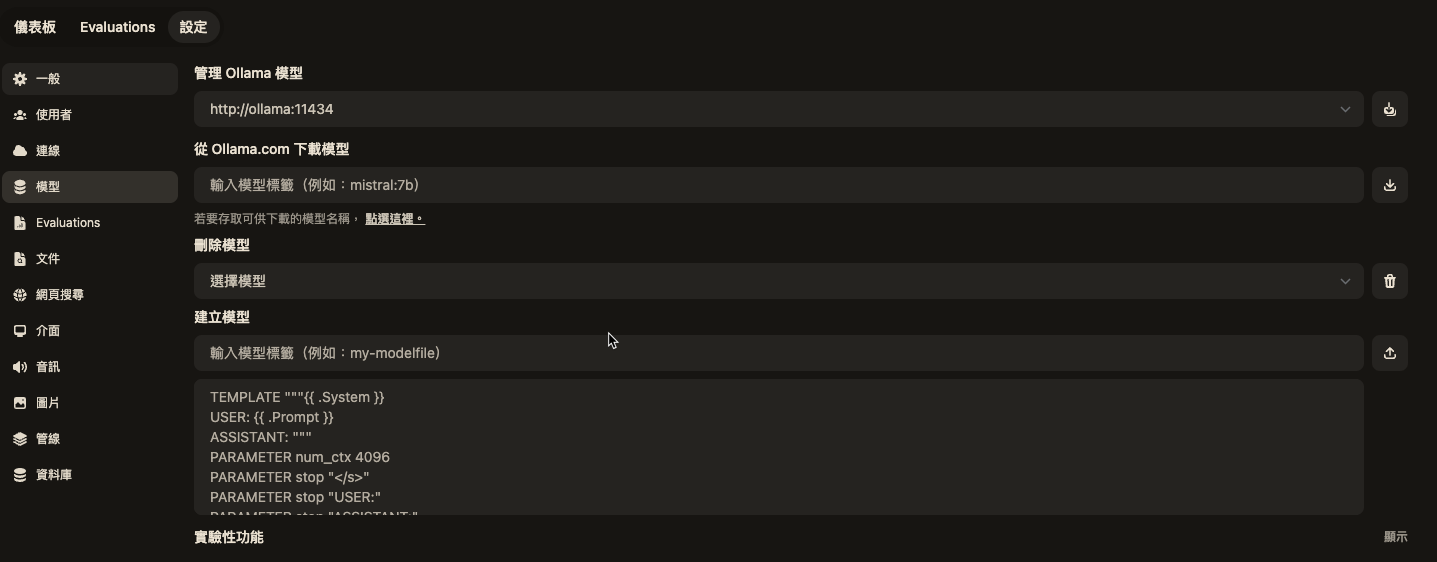
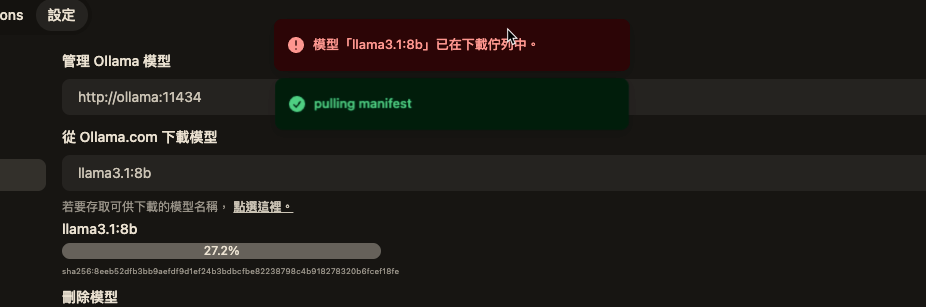
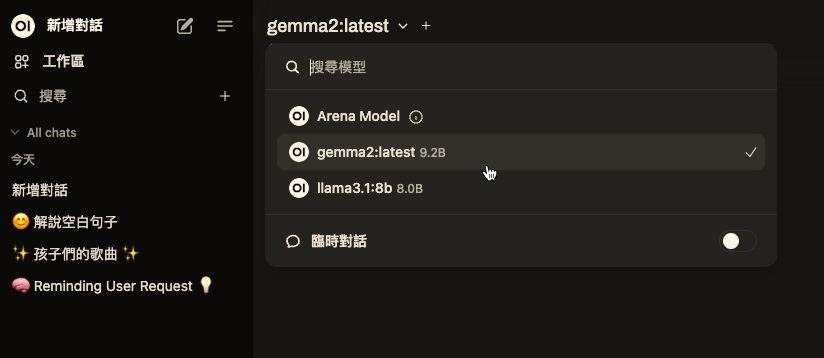
openwebui也可以接openai的api 先到這邊申請一組key
https://platform.openai.com/
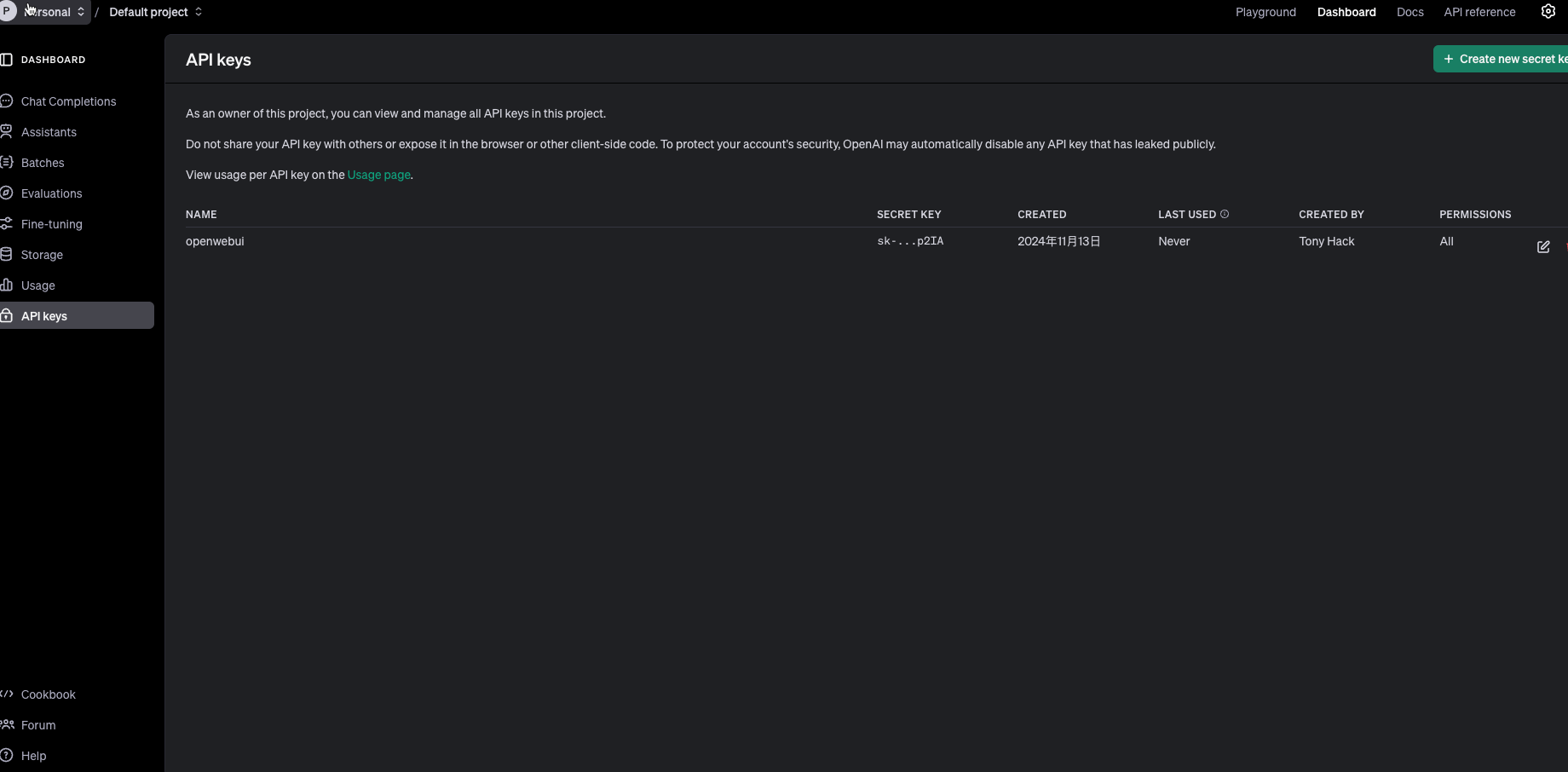
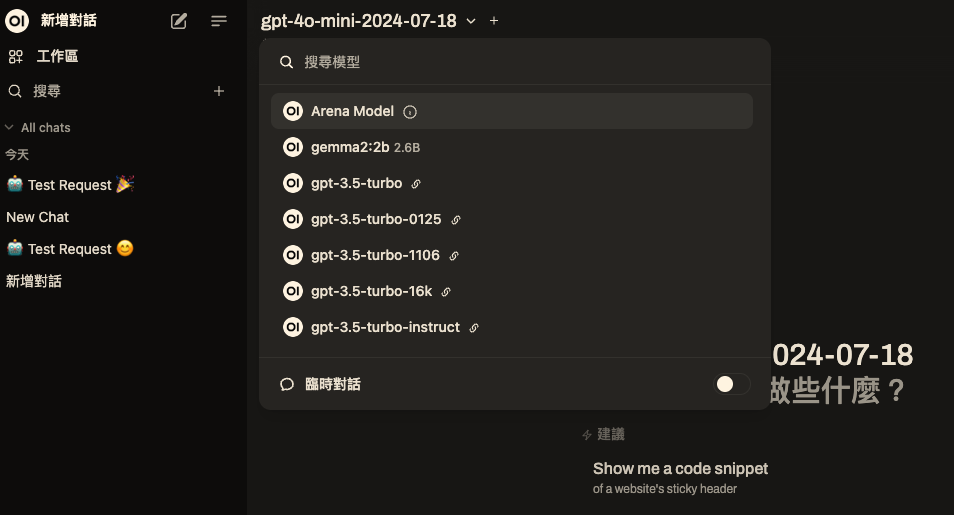
後台加入apikey

首頁就會有gpt3 or gpt4可以使用
透過以上步驟,您已成功部署 Open WebUI,並透過網頁介面與 Gemma 2 模型互動。Open WebUI 提供了更友善的操作方式和更豐富的功能,讓您可以更方便地探索 LLM 的應用。
您現在已經掌握了在 Google Cloud 上使用 GKE Autopilot、Ollama 和 Open WebUI 部署並運行開源 LLM 模型 Gemma 2 的技能,可以構建自己的聊天機器人應用程式了!
有了這些知識,您可以: * 進一步客製化您的聊天機器人,例如調整模型參數、設計不同的對話風格等。 * 將您的聊天機器人整合到其他應用程式中,例如網站、客服系統等,提升使用者體驗。 * 探索更多開源 LLM 模型,例如 LLaMA 2、Vicuna 等,打造功能更強大的聊天機器人。 * 利用 GKE Autopilot 的自動擴展和成本優化功能,有效控制聊天機器人的運行成本。